
Scaling with Karpenter: The Good and The Bad
A candid story of trading Cluster Autoscaler for flexibility in Kubernetes scaling.

We first discovered Karpenter back in 2023. At the time, Kubernetes scaling for us meant living with the Cluster Autoscaler on EKS. It was stable, predictable, and well documented. But it was also rigid and slow: new nodes could take minutes to join, and the only way to tune behaviour was by pre-scaling some placeholder pods.
Karpenter promised something fundamentally different. Instead of relying on ASGs, it provisions EC2 instances directly, based on rules you define with just two CRDs: Provisioner and AWSNodeTemplate. That means instead of being locked into a fixed pool of machines, Karpenter can pick the best available and cheapest instance at runtime.
That idea was powerful enough for us to give it a try in our lower environments, as it wasn’t production-ready at the time.
Why We Looked at Karpenter
The motivation was simple: our workloads were scaling up and the cracks in Cluster Autoscaler were starting to appear.
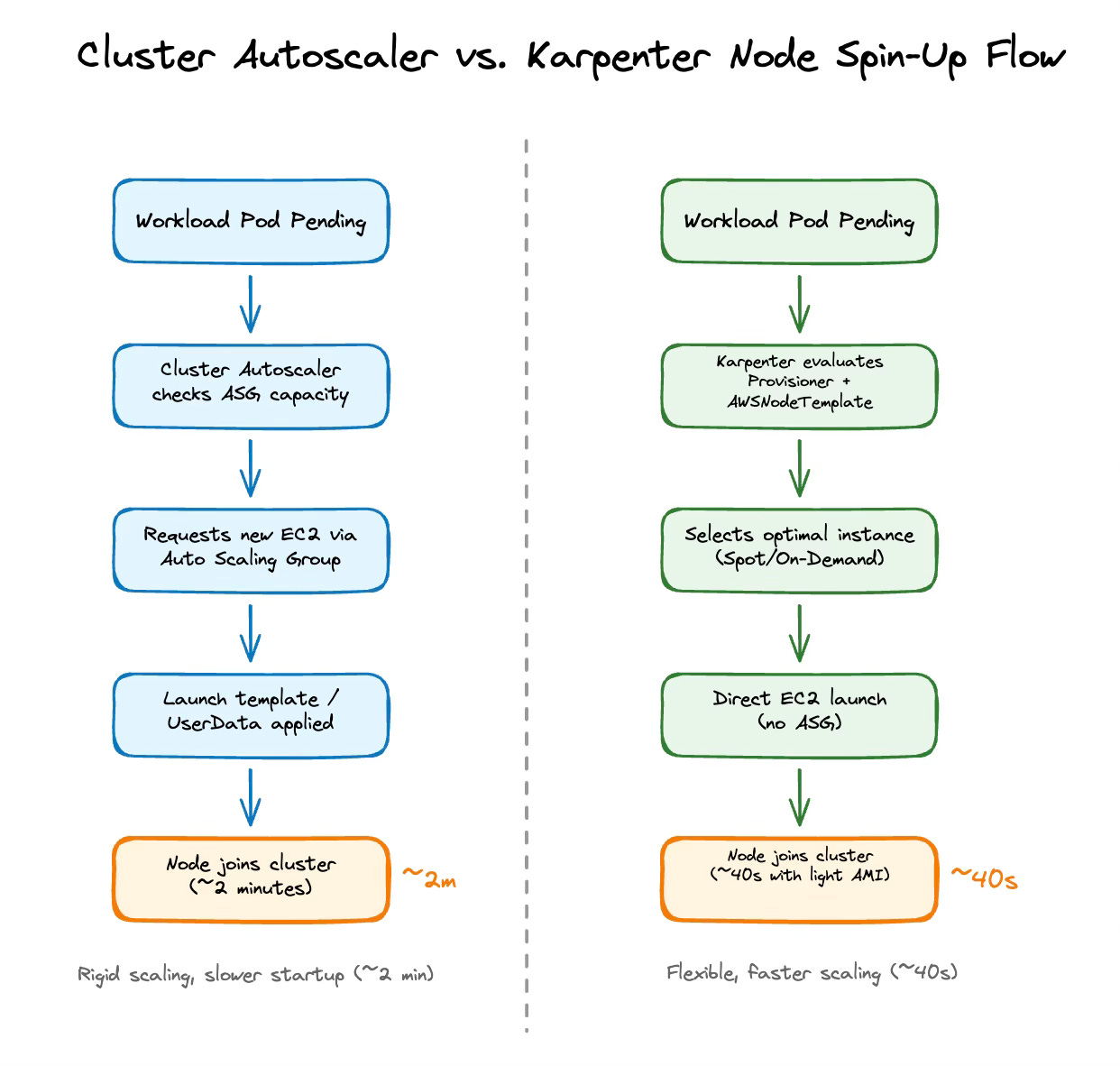
Speed: Cluster Autoscaler could take about 2 minutes for a new node to become ready. With Karpenter (plus a lightweight AMI), it was closer to 40 seconds.
Flexibility: We wanted more freedom in choosing machines, mixing on-demand with spot instances, and selecting from a wider set of EC2 types.
Cost: By leaning on spot capacity and flexible provisioning, we could save up to 40% on compute without changing how workloads were deployed.
Drift Detection: Karpenter can detect when nodes become outdated or misaligned with current requirements and proactively replace them. (Note: This feature was introduced in later versions, not available in early 2023)
This wasn’t about chasing new tech for the sake of it rather it was about building flexibility into our scaling model so we could adapt under unpredictable demand.
The Early Days
When we started using Karpenter in 2023, it was far from stable. The stability journey was gradual:
Pre-v0.32: Breaking changes were common, sometimes with every minor release
v0.32: Marked a turning point where APIs started stabilizing
v1.0.0: Finally delivered the production-ready stability we needed
Some of the specific pain points:
Cryptic errors: Pods stuck in Pending with vague “capacity not available” messages. Nodes failing silently because of IAM misconfigurations.
IAM complexity: We had to manage multiple roles (controller, node bootstrap, EC2 instance profile). If trust policies didn't line up, nodes would launch but fail to register. For example, if the node instance profile lacked the necessary EKS worker node policies, pods would stay pending even though EC2 showed healthy instances.
Breaking changes:
v0.27 changed default consolidation logic, breaking scaling policies.
v0.32 overhauled scheduling APIs, forcing CRD rewrites.
Despite all this, the potential upside kept us going.
How Karpenter Works (in brief)
Cluster Autoscaler depends on Auto Scaling Groups: you define which instances you want, and the autoscaler requests capacity by resizing those groups.
Karpenter removes ASGs from the equation instead:
A pod is pending.
Karpenter evaluates your Provisioner and AWSNodeTemplate. {in 2023}
It chooses the cheapest + most available EC2 type that satisfies requirements (on-demand or spot).
It launches the instance directly and joins it to the cluster.
That direct model is what makes Karpenter faster and more flexible.
What Worked, What Hurt, What Broke
After months of experimenting, tweaking provisioners, and firefighting, we started to see a clearer picture of what Karpenter actually meant for us. It wasn’t just theory or benchmarks anymore, it was lived experience. The results were mixed: genuine wins, persistent frustrations, and a few near-disasters that taught us hard lessons.
Here’s how it really played out.
The Good: When Demand Hit Us Out of Nowhere
The first time Karpenter proved its worth. It was a weekday afternoon, a fairly low-traffic period, when suddenly one of our events got picked up on social media. Within minutes, requests shot up nearly 3×.
With Cluster Autoscaler, this would’ve meant a painful 2–3 minutes of waiting for new nodes. Instead, Karpenter spun up fresh capacity in close to 40 seconds. Pods scheduled almost immediately, the customer impact graph barely wobbled.
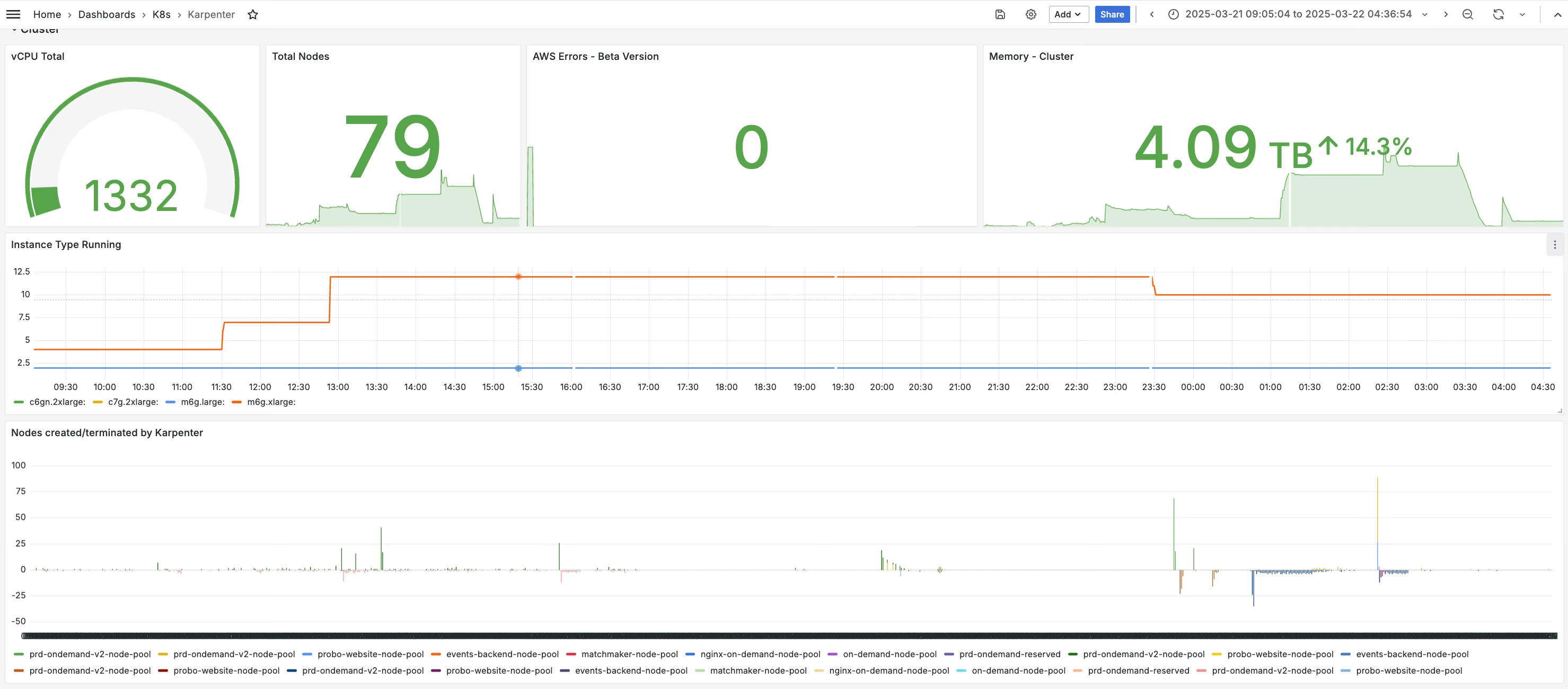
The second win was cost. By default, Karpenter mixed spot and on-demand intelligently, shaving ~40% off our compute bill without needing us to micro-manage instance types. That kind of flexibility and no more rigid ASGs felt transformative.
The third win was subnet planning. With Cluster Autoscaler was always a headache. IP exhaustion could quietly block scaling, and fixing it meant manual subnet juggling across availability zones.
Karpenter flipped that model entirely. As long as we tagged subnets with karpenter.sh/discovery=<cluster-name>, it could shift nodes across them automatically. We could add bigger subnets without re-architecting capacity, and scaling bottlenecks from IP exhaustion mostly disappeared.
And by the time v1.0.0 shipped, Karpenter was finally stable enough. It went from “experimental toy” to a critical part of our stack.
The Bad: Living on the Edge of Release Notes
But before v1.0, running Karpenter felt like being part of a beta program we never signed up for. Some minor upgrades came with breaking changes. Provisioners that worked last week suddenly refused to validate this week.
The documentation made things worse. Most of it still assumed EKS clusters used the old aws-auth ConfigMap, even though AWS had deprecated it in favor of EKS access entries back in 2022. We ended up digging through GitHub issues more than reading official docs.
And then there was setup overhead. IAM roles, trust relationships, provisioner tuning. It was never a plug-and-play install. Every new environment meant hours of yak-shaving before workloads could actually run.
These weren’t “cute edge cases.” They were the kind of pain that leaves scars where you’re refreshing Grafana dashboards while combing through opaque controller logs, trying to understand why autoscaling, the thing you promised would be smoother, is actively betraying you.
When to Consider Karpenter
Choose Karpenter if:
Node startup latency is hurting your workloads.
You’re under cost pressure and want to use spot effectively.
You want flexibility to adapt to unpredictable demand.
Stick with Cluster Autoscaler if:
Stability > flexibility for your environment.
Your clusters are small, predictable, or heavily regulated.
Your team doesn’t have bandwidth to manage IAM and configuration complexities.
Recommended starting point: Begin with the latest v1.x stable release. Avoid older versions entirely.
Final Reflection
Adopting Karpenter early wasn't smooth. We endured cryptic errors, broken upgrades, and IAM headaches. But the payoff was real: faster scaling, lower costs, and flexibility that Cluster Autoscaler couldn't match.
The real lesson isn't about Karpenter itself, it's about pragmatic engineering. Sometimes the safe choice (Cluster Autoscaler) is fine. But sometimes, the risky bet (Karpenter in 2023) pays off because it unlocks new ways to scale under pressure.
In our case, it was worth it. If you're hitting the walls of traditional autoscaling, it might be time to consider the trade-offs.
What’s Next
Considering Karpenter for your setup? The implementation has its gotchas—IAM configuration, provisioner/Nodepool tuning, and migration strategies all need careful planning. If there's enough interest, I'll cover the practical setup details and lessons learned in a follow-up post.