
Scaler : our in-house scaling solution
“nuts and bolts” walkthrough of how We tied Google Calendar to scaling logic.

Integrating Google Calendar as the “Control Plane”
The first building block of Scaler was surprisingly non-technical: a shared Google Calendar. We realized that our traffic spikes weren’t random — they were event-driven. And who in the company knew about events ahead of time? The marketing team. Instead of building an elaborate custom interface, we decided to piggyback on something everyone already used and trusted.
Step 1: Set up a shared calendar
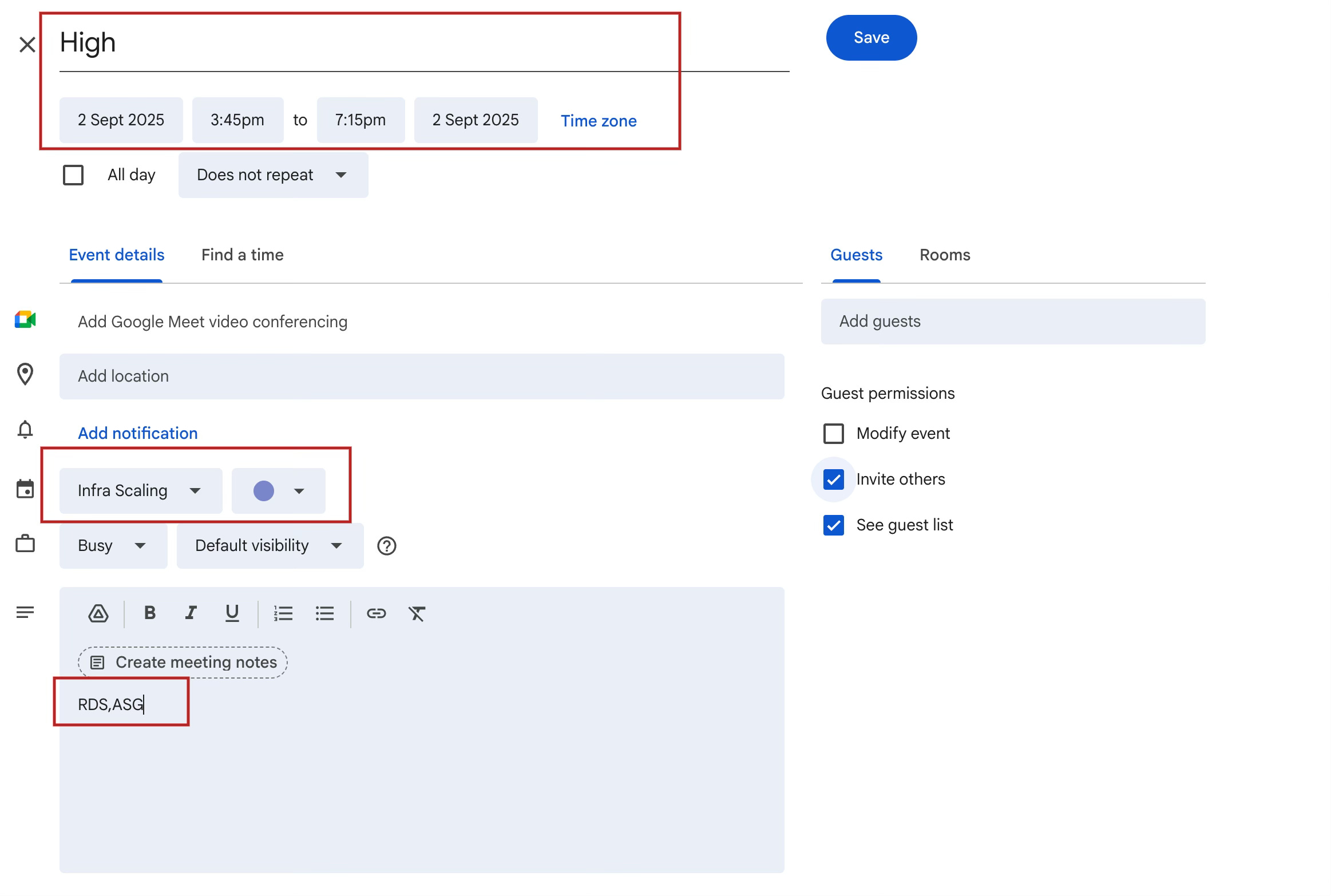
We created a dedicated Google Calendar called Scaling Events. Access was shared with engineering and marketing. Each person could add or edit events based on their role. Engineers got the calendar ID, which let us fetch the data programmatically, while non-technical teammates just saw “another calendar” show up in their Google Calendar UI.
Step 2: Encode scaling intent as events
Each event in the calendar represented a scaling profile. The title was simple and human-readable—high, medium, night, low—and always tied to a cricket match, campaign, or product launch. These were created after consulting the marketing/business team, so engineers didn’t have to guess when to scale.
Step 3: Describe what to scale
The event description field became our schema. Inside it, we listed which resources needed scaling—comma-separated:
HPA, ASG, RDS, REDISThat way, a marketing manager could say “this IPL playoff match is high traffic, scale Redis and RDS accordingly”without touching infrastructure code.
Step 4: Process the inputs
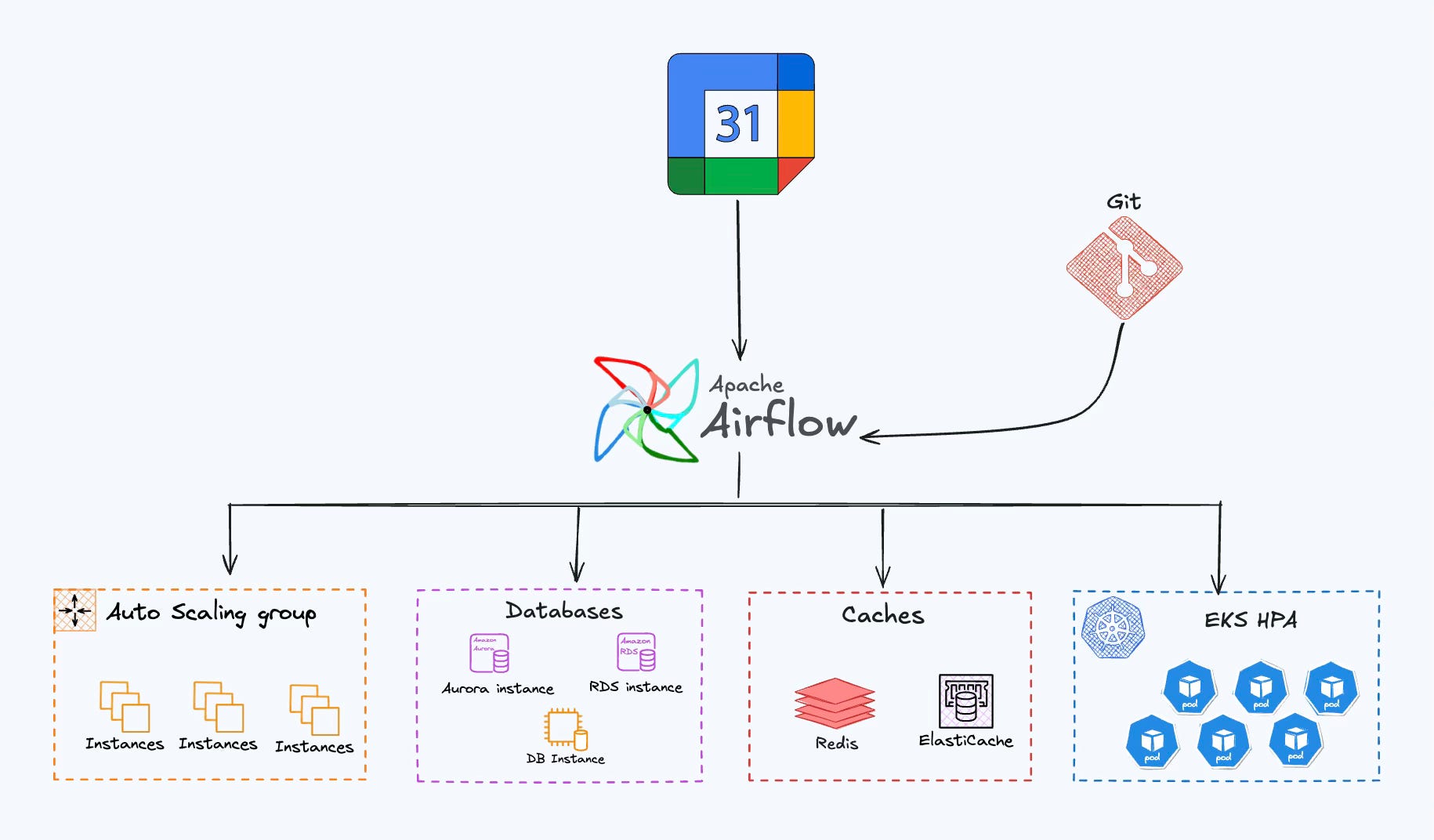
Once these events were in place, the next step was automation. We wrote an Airflow DAG to poll the Google Calendar API every 10 minutes. Any scheduler would have worked, but at Probo we leaned heavily on Airflow for orchestrating time-based tasks, so it fit right in.
Airflow DAG: Calendar → Scaling Actions
The DAG worked in two layers:
Template Definition
A generic scaling_template described how each resource could scale across different traffic levels. It covered everything from RDS instance types to Redis dataset size, broken down by profiles (default, medium, high, night).
Example (simplified for RDS):
{
"RDS": {
"<ENVIRONMENT>": [
{
"name": "<Name of the RDS Cluster>",
"scaling_enabled": "<true/false>",
"instance_ids": ["<RDS Instance Names>"],
"traffic_config": {
"default": {
"instance_type": "<db.instance.type>",
"min_capacity": "<number>",
"max_capacity": "<number>"
},
"medium": {
"instance_type": "<db.instance.type>",
"min_capacity": "<number>",
"max_capacity": "<number>"
},
"high": {
"instance_type": "<db.instance.type>",
"min_capacity": "<number>",
"max_capacity": "<number>"
},
"night": {
"instance_type": "<db.instance.type>",
"min_capacity": "<number>",
"max_capacity": "<number>"
}
}
}
]
},
"calendar_id": "<YOUR_CALENDAR_ID>@group.calendar.google.com"
}Configuration in Git
To keep things auditable, environment-specific configs were stored in Git. Every change (say, adding a new RDS cluster to scale) was reviewed like any other code change.
Example (simplified):
{
"RDS": {
"PROD": [
{
"name": "main-db",
"scaling_enabled": true,
"instance_ids": ["db-instance-1", "db-instance-2"],
"traffic_config": {
"default": {
"instance_type": "db.t4g.medium",
"min_capacity": 1,
"max_capacity": 1
},
"medium": {
"instance_type": "db.r6g.large",
"min_capacity": 3,
"max_capacity": 3
},
"high": {
"instance_type": "db.r6g.xlarge",
"min_capacity": 10,
"max_capacity": 50
}
}
}
]
},
"calendar_id": "<YOUR_CALENDAR_ID>@group.calendar.google.com"
}This two-step structure—templates for patterns, Git for actual config—kept the system both flexible and reviewable. Marketing could decide when to scale, engineers defined how scaling worked, and Airflow acted as the glue in between.
Closing thoughts
What we built with Google Calendar + Airflow may look deceptively simple, but it was the foundation of Scaler. Instead of chasing fancy abstractions, we gave the business team a language they already understood—calendar events—and wired it directly into infrastructure logic.
“This meant engineers weren’t firefighting during every cricket match, and marketers could directly influence capacity without opening a single AWS console.”
That said, this is just the first layer. There’s a lot more beneath the surface—like:
The processing logic: how calendar events were parsed, mapped to Git configs, and converted into scaling actions on AWS resources (ASGs, RDS, Redis, HPA).
Safety nets & guardrails: how we ensured that a bad calendar entry or misconfigured template didn’t accidentally scale down production during a high-stakes event.
Real-world outcomes: cost savings, reliability gains, and some hard lessons learned about prediction vs. reaction.
If you’d like me to go deeper into these areas, let me know—I can cover them in the next post.