
How we scaled our Monolith to execute 250Mn+ trades in a day?
This post was originally published on engineering.probo.in


You might have read dozens of articles around Monolith vs Microservices. And most of them suggest to keep your distance with the microservices until you have solid reasons to do so.
But micro-services are tempting, you can get these solid reasons well early into your development cycle or as late as never. There are numerous articles on how to split monolith to microservices. But very few articles talk about how to do your monolith right. This is an attempt at the latter.
Context
At Probo, we are a small team of about 30 engineers. One basic principle we try to adopt is to keep things simple. As a result, we are running a monolithic version of our backend from day 1 and we are well into our 4th year. We have a seen a journey of 0 trades to 250Mn+ trades in a day.
Things that helped us in this journey
Code structure
Our code structure is inspired by Domain Driven Design. From the start itself we had three major bounded contexts that we recognised and developed the code around it.
It was as simple as — User (profile, referral, etc), Trading (order-management, trade-management etc) and Payments (user balance, transaction history etc) ecosystem.
We tried to keep interaction between these contexts loosely coupled. Most of the database joins were in their own bounded contexts.
We had a very basic layered code architecture — Presentation → Domain logic → Data management layer.
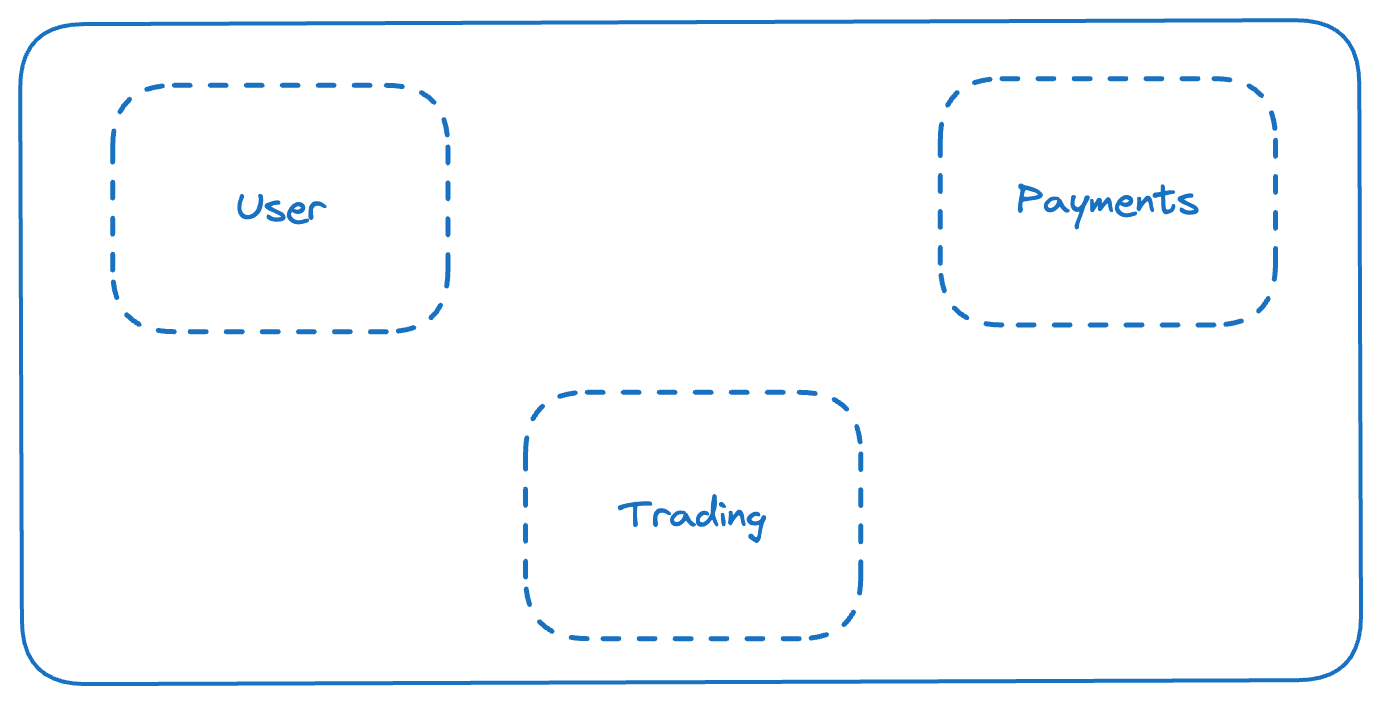
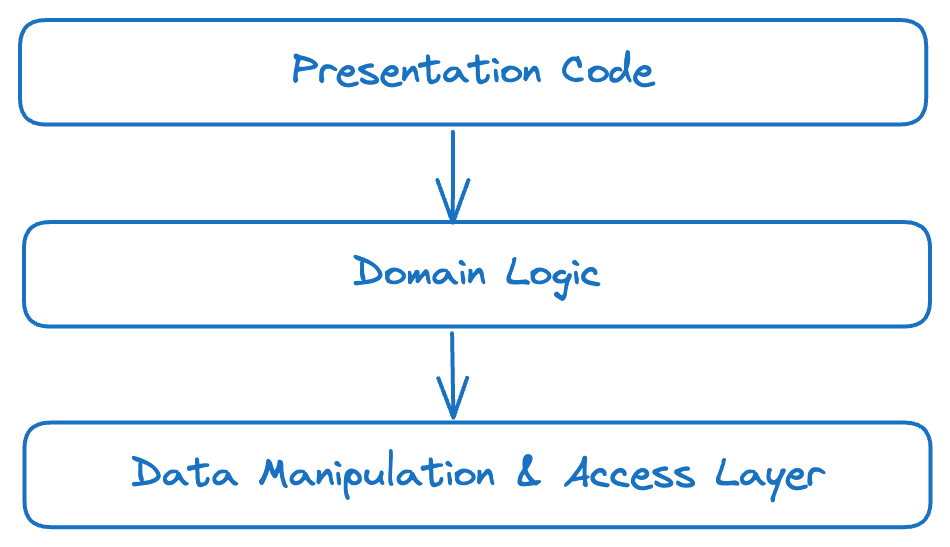
Concept of services in a monolith, with a focus on preventing domain leakage.
If required each individual service used to communicate with other service through service<>service methods and not by data layer.
Splitting into Server & Worker modes
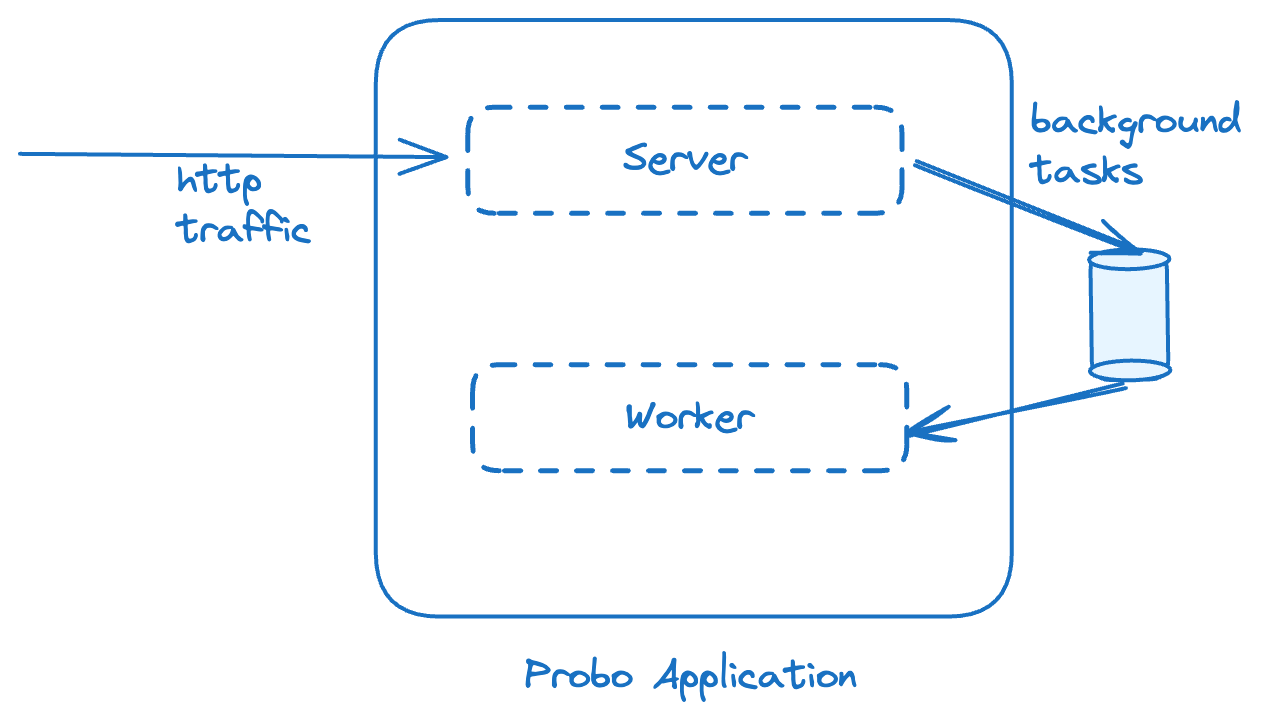
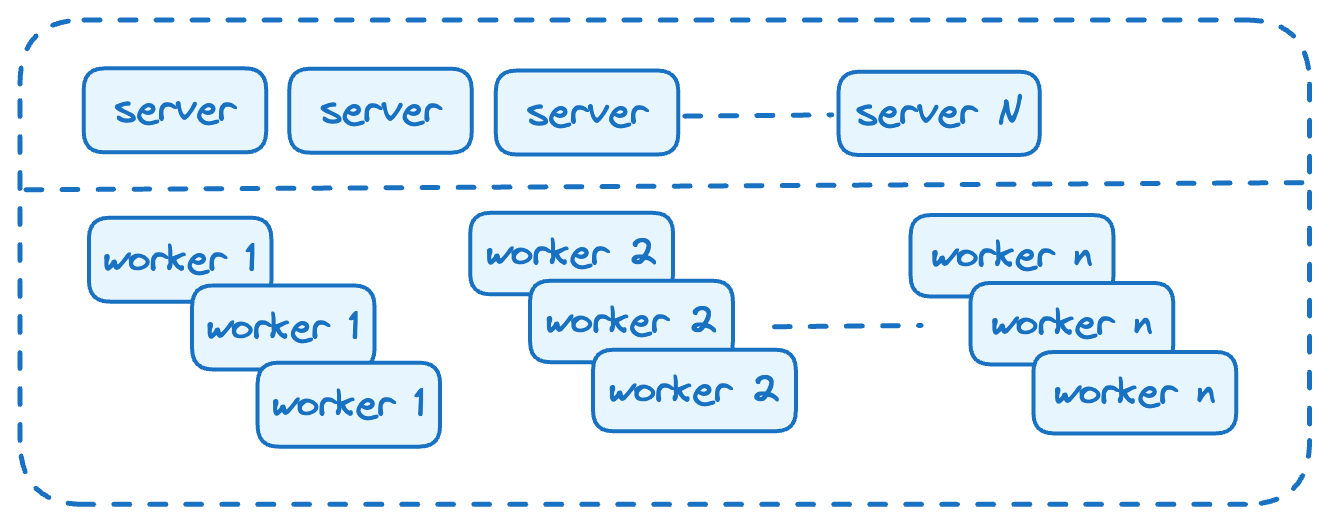
We encountered performance issues well early into our journey when everything was handled with a single process. To solve, we first identified the background tasks and separated them out of server process.
As a result, both server process and various worker processes could now independently scale without affecting one another.
The bottleneck is always the database
We use AWS managed database offering — MySQL RDS
As mentioned by Kailash Nadh, “97.42%* of all scaling bottlenecks stem from databases”. And we can confirm that it is true!
Focus on fundamentals. “No Indexes” or “incorrect Indexing” is the most popular answer I get during my interviews when I ask about downtimes.
Leveraging performance insights of RDS helped us pin point multiple issues. We were able to solve long running queries, reduce expensive queries, understand transactions.
Investing time in learning about database parameters helped us scale our database better and avoid downtimes. This is required even when you are using a managed database like AWS RDS.
One thing we did actively was to post slow queries on slack — this kept us on toes!
Use of database proxy helped scale our application horizontally, without worrying of connection limitations.
On a team level, everyone had access to database monitoring dashboards, that really helped to understand and learn about the issues together. I have seen multiple organisations which limit database access to a certain team, namely devops or dba team which I feel limits the developers to understand and write optimised code.
Caching Layer
Initially, we started investing in our caching layer to ease of pressure on our database and improve API response times.
The setup quickly expanded to solve other use cases like Leaderboard, Authentication, Realtime, Feed, Graphs etc.
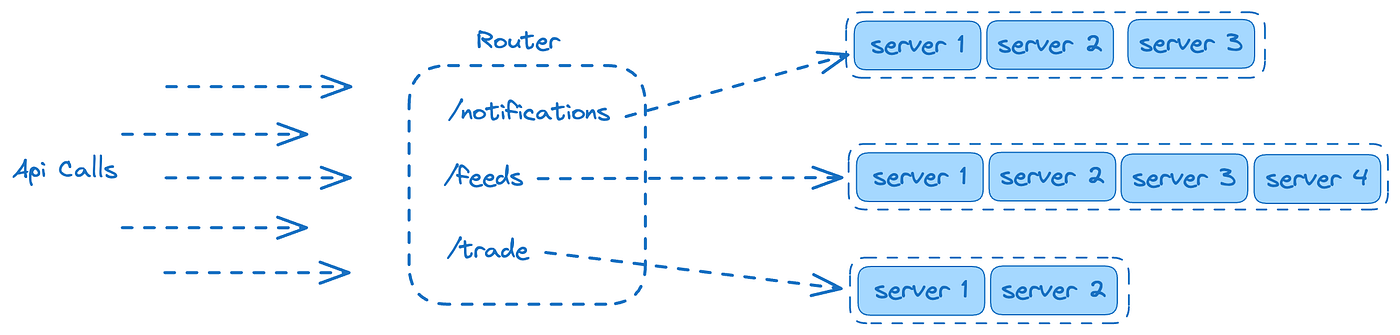
Independent endpoint scaling
Segregating our high throughput endpoints, helped us in scaling horizontally and help isolate issues faster.
Example — when a notification is sent to our users, we update the read/view status on our end. This is a burst traffic that impacts other APIs performance. Identifying these Api’s and redirecting to their own set of dedicated instances helped us prevent slowness.
Language Specific Tweaking
Whatever language you pick, there are always some basic level of configuration tweaking that is required to scale efficiently.
We use NodeJS majorly, and since it is single threaded we run it in cluster mode using PM2 to efficiently utilize our compute resources.
Some other configurations like
--max-old-space-size=SIZE(sets the max memory size of V8's old memory section),--prof(for profiling) were used
Observability & Alerting
We spent a considerable amount of time in setting up our observability right. I wouldn’t say it is perfect, but it gets the job done.
Our logging infrastructure is self-hosted, a simple Elasticsearch cluster with Kibana. Though it looks simple, but scaling Elasticsearch has been a challenge.
Initially, the scale on our infrastructure was a self-inflicted scale, since a lot of logs were not useful. To tackle this problem, we created a simple library — https://engineering.probo.in/from-chaos-to-clarity-the-evolution-of-logging-from-unstructured-to-structured-part-1-78b059bed362
For metrics, we utilised last9. It helped us to spend time on creating effective dashboards instead of spending time on installation/maintenance & scaling.
Last9’s alert manager helped us in democratising alerts among our teams. Despite a monolith, each team owned their metrics and alerts.
Not everything is good in Wonderland.
Deployment time
There is a significant increase in deployment time due to
CI Pipeline tests and checks
Rolling deployment, hence the time taken to complete the deployment is directly proportional to the number of instances
Fear of change
There is always a fear that a change might take complete service down. This has resulted in apprehensions in the frequency of deployments or during high traffic times, etc.
Multiple dependencies & Resource Sizing
Dependencies in terms of databases, cache etc keep on growing with use cases. Thus increasing your surface area for downtimes.
Horizontal scaling also puts pressure on your resources, like Database connections, which leads to unoptimized sizing. Proxy & Pooling to the rescue!
In conclusion, it’s quite possible to scale a monolithic architecture to handle a high volume of transactions, given the right practices and considerations.
We’ve focused on keeping our codebase simple and structured, while there are challenges but we’ve found solutions that work for us. The journey has been rewarding and educational, and we hope our experience can provide useful insights for others facing similar scaling challenges. At Probo, with increasing scale, we get regular opportunities to re-evaluate our architecture. Stay tuned for more updates!
If you enjoyed reading this, you’re one of us — someone who loves solving deep technical challenges. We’re building high-performance systems and tackling complex engineering problems every day.
Follow - https://engineering.probo.in/