We often get so excited about doing “technical work” that we forget first principles and end up deep in yak shaving — optimizing the wrong thing, adding complexity no one asked for, or celebrating fixes that shouldn’t have existed in the first place.
At Cricket Scale, some of the most impactful wins weren’t about clever infra or cutting-edge tools. They came from the not-so-technical grind: listing APIs, questioning every spike, trimming redundant calls, and removing waste. Unglamorous chores, but they saved us more than any scaling trick ever could.
Thanks for reading Thoughtful Engineering! Subscribe for free to receive new posts and support my work.
So in this post, I’ll start discussing those chores — the work that rarely makes it into conference talks, but quietly makes systems faster, cheaper, and easier to run.
1. Questioning the Existence
During load testing, we noticed a few APIs with throughput that stood out — far higher than expected. Our tests mimicked real user behavior in the app, mapping common flows to the APIs behind them. That exercise quickly pointed us in the direction of listing every API and looking at the numbers: throughput, p90/p95/p99 latencies, average response times, and error rates.
why are these APIs being called so often?
The first question we asked was simple: why are these APIs being called so often?
Instant Refresh Assumptions — Frontend logic assumed users always needed the “freshest” state, so certain endpoints were being hit far more frequently than necessary.
Reloads and Missed Caching — Some APIs reloaded every time a user landed on a key screen (like the home page), even when nothing had changed. A few endpoints also slipped past client-side caching. Each case seemed small in isolation, but multiplied at DAU scale, they created massive unnecessary load.
Take the home page as an example. Every time a user landed there, our feed API was called — which made sense, because the feed had to be fresh. We couldn’t afford to show expired events.
But alongside the feed, our hamburger API was also being triggered on every visit. This endpoint pulled details like user balance, skill score, and help ticket status — things that didn’t need to be refreshed with the same urgency as the feed.
Probo’s Home Page
Because the home page has the highest DAU, the hamburger API ended up matching the feed API in throughput. And that wasn’t the end of it — each hamburger call fanned out into other services, hitting the wallet service and skill score service to fetch details.
So what looked like a harmless reload turned into a cascade of unnecessary load, inflating throughput across multiple systems. At scale, this kind of oversight meant we were spending infra and engineering effort just to serve data users didn’t actually need that often.
why does this API exist at all?
Once we answered why they were called so often, the next question was even more fundamental: why does this API exist at all?
Zombie APIs — Endpoints left behind from old experiments or features long since retired.
Unfinished Features — Half-built ideas that never made it to production, but still left endpoints active.
Cleaning these up wasn’t glamorous work — it meant auditing flows, talking to product managers about what was still relevant, and carefully deprecating endpoints so nothing broke. But each removal was one less thing to scale, one less source of noise in our metrics, and one more bit of clarity in how the system actually worked.
Does this product feature even matter?
We didn’t stop at APIs. We went a step further and questioned the product features themselves.
We made a list of APIs that were expensive to run and mapped them against their importance to the user experience. Wherever we saw features that weren’t contributing much, or had very low to no usage, we sat with the product team and evaluated whether they were still worth keeping.
In many cases, the honest answer was no. Those features were quietly adding cost, complexity, and operational overhead without giving users any real value. With the product team’s support, we removed them altogether.
At scale, sometimes the best optimization isn’t caching or tuning — it’s simply deleting what no longer matters.
What about expensive but necessary APIs?
Then there were cases where the APIs were genuinely expensive but couldn’t just be deleted. A good example was expired or past events in which users had participated — essentially their long-term portfolio.
For an app that had been live for more than a year, this meant a massive amount of historical data. Fetching and rendering all of it on demand didn’t make sense — the cost was high, the latency was painful, and most users only cared about their recent activity.
Here, the solution wasn’t removal, but redesign. Instead of hitting expensive APIs every time, we thought carefully about what actually needed to be shown up front, and what could be deferred, summarized, or tucked behind pagination.
download events older than 60 days
This was another kind of grind — not heroic infra scaling, but thoughtful product and engineering decisions about what truly mattered to the user experience.
2. The Ops Grind
Not all of the grind was about APIs or product features. A big part of scale was operational — managing observations, tuning infra, and staying ahead of limits.
Observability and Checklists
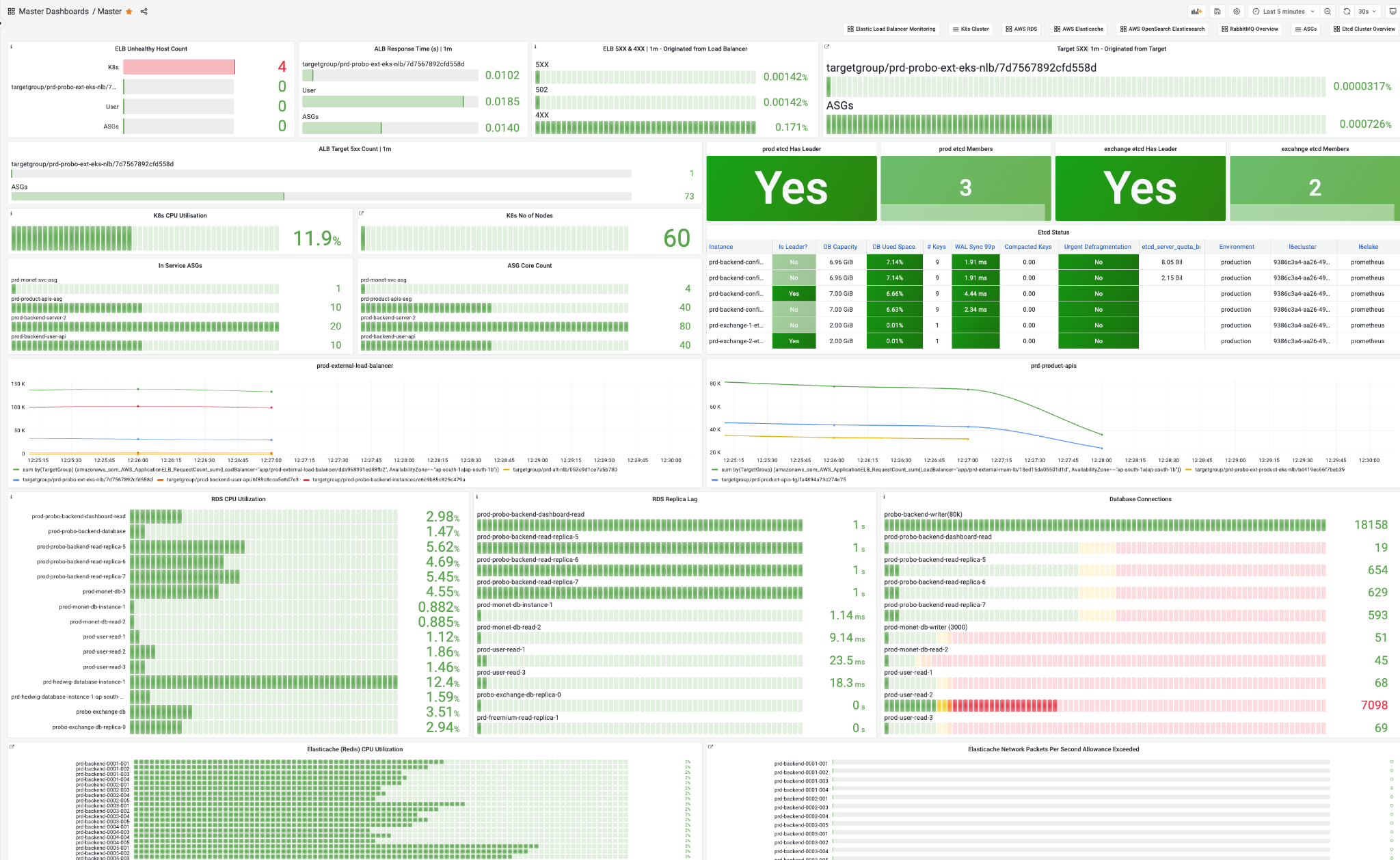
We built a top-level system view, inspired by Dream11’s observability work, that could instantly tell us which service or dependency in the entire system was having an issue. And with the help of a master dashboard, we had the ability to drill down further — moving from the big picture to the exact service, API, or dependency causing trouble.
master dashboard
👉 If you’d like me to go deeper into how we approached observability — from designing top-level views to drill-down dashboards and fine-tuning alerting — let me know in the comments. That might be the focus of a future post.
Alongside this, we relied heavily on checklists, timely enhancements, and alert fine-tuning. This wasn’t glamorous, but it gave us clarity and helped us avoid firefights turning into outages.
Infra Limits and Quotas
From the infrastructure side, the grind looked different but was just as important. Scaling wasn’t only about adding nodes or tuning autoscalers — it also meant making sure we never hit the practical limits of the cloud.
Cloud providers usually enforce soft limits on resources, and if these are overlooked, they can easily cause downtime during peak events. To stay ahead, we sat with each team to understand their scaling requirements and helped set their scaling configs in place well in advance. Depending on their needs, we also did capacity reservations so resources were guaranteed when traffic spiked.
Beyond quotas, we focused on resilience:
Creating backups so we could quickly recover in case of failures.
Preparing SOPs for incidents so everyone knew what to do if something went wrong.
Warming up redundant dependencies so failover paths were ready and wouldn’t add cold-start latency during a match.
None of this was glamorous, but without it, all the scaling design in the world wouldn’t have mattered — the system would have hit a ceiling we didn’t control.
The Playbook Grind
Scaling wasn’t just about systems — it was about people. For the first day of the largest cricketing event, the IPL, we developed detailed SOPs that laid out exactly how things would run. Nothing was left to chance.
A game marshal was appointed to oversee coordination.
We documented the points of contact across customer experience, business, marketing, and other key teams.
A dedicated Slack channel was created for real-time coordination.
An on-call rotation was set up so engineers knew exactly who was responsible at any given moment, ensuring quick response without chaos.
We defined pre-match activities (scaling checks, quota reviews, dry runs), during-match activities (traffic monitoring, alerts, notifications), and post-match activities (user comms, debriefs, reporting).
Each step was written down, and reviewed. It wasn’t glamorous engineering work, but it created alignment. Everyone knew their role, the handoffs were smooth, and there was no confusion when the real traffic hit.
Closing Thoughts
The “not-so-technical grind” rarely makes it into architecture diagrams or scaling war stories, but it’s often where the real wins come from. Listing APIs, questioning why they exist, debating product features, preparing infra checklists, and writing SOPs — none of it is glamorous, but all of it compounds at scale.
Sometimes the most powerful scaling move isn’t adding more infra. It’s asking simple, first-principle questions and having the discipline to trim, prepare, or delete.
Thanks for reading Thoughtful Engineering! Subscribe for free to receive new posts and support my work.