
Cricket Scale, Part 1 — EC2 vs Kubernetes
Picking the Right Scaling Foundation

This is an ongoing series on Cricket Scale — a kind of scale that’s different from normal. It’s sudden, spiky, and event-driven, and here I share how we at Probo built systems to handle it.
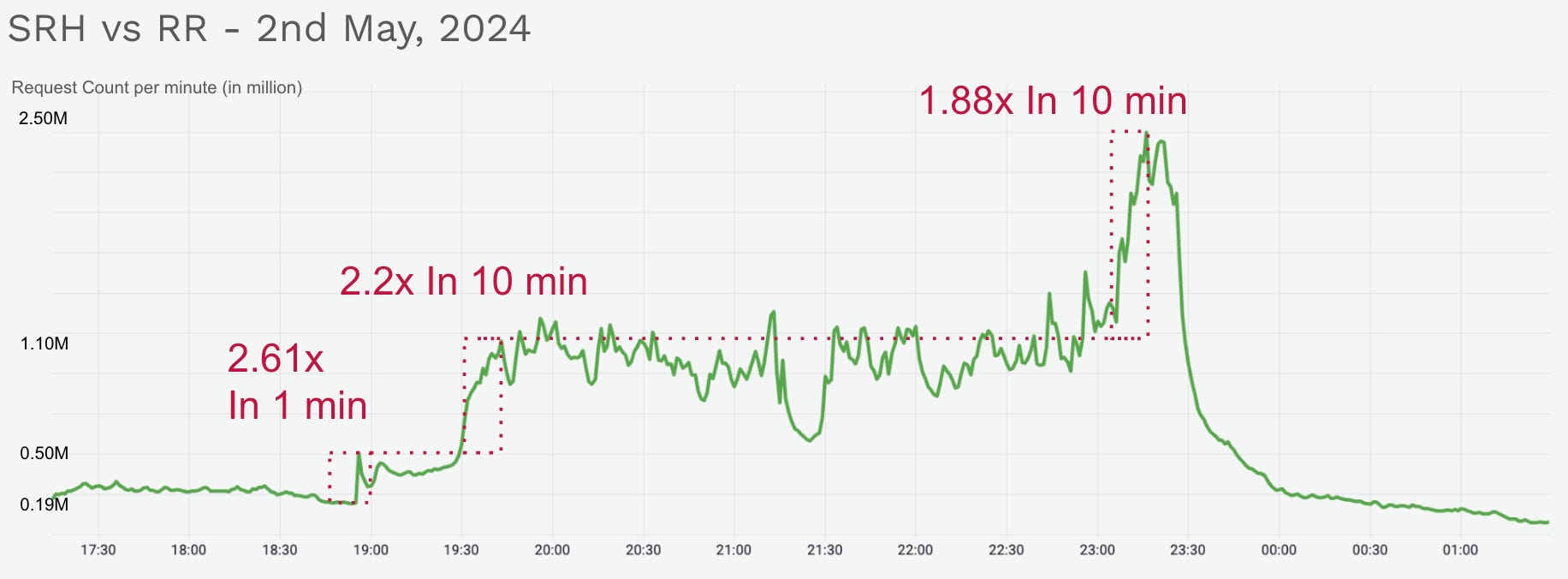
In the second year of Probo, even regular India cricket matches (not just IPL) pushed our systems to the edge. Traffic patterns during the game were sudden, steep, and unpredictable.
Our EC2-based setup, which relied on autoscaling groups, was reliable but slow to react. Scaling new instances could take minutes, while traffic spikes arrived in seconds. We realized this approach might not hold up as Probo grew. We needed something quicker.
At the same time, we were tinkering with Kubernetes. It promised more configurable scaling — the ability to tune how workloads scaled up and down, to use horizontal and vertical pod autoscalers, and to react to more than just CPU or memory.
EC2 — The Baseline
When we started, running Node.js applications on AWS EC2 instances was straightforward:
Simple model: launch an instance, deploy the app, attach it to a load balancer.
Autoscaling groups: scale in/out based on CPU and memory
Predictable performance: Node.js processes on EC2 gave us stable latency under load.
We used pm2 as the process manager, running multiple processes per instance — usually n-1, where n is the number of cores — to maximize CPU utilization while leaving some headroom.
This setup worked fine for steady traffic and moderate growth. But at cricket scale, the coarse granularity of EC2 autoscaling meant we were always a step behind the spikes.
Kubernetes — The Next Step
Kubernetes looked like the natural answer:
Configurable scaling: horizontal and vertical pod autoscalers, custom metrics, and more control over how workloads scale up and down.
Bin packing: schedule multiple pods with different resource needs onto the same EC2 node, making better use of CPU and memory.
Faster churn: pods can come up quicker than booting whole VMs.
On paper, it solved the problems we were facing. But our early results showed the opposite — applications that ran smoothly on EC2 performed worse when moved to Kubernetes.
The reasons became clear: networking overhead, noisy neighbors, CoreDNS bottlenecks, and the operational burden of tuning clusters under sudden bursts. I’ve written about some of these challenges in more detail here: Production-Grade Pain: Lessons From Scaling Kubernetes on EKS.
The Trade-offs
In theory, Kubernetes gave us more knobs to tune. In practice, we had a small team and IPL was around the corner. There were already higher-priority tasks on the table, and investing deep time into tuning Kubernetes clusters wasn’t realistic.
So we took the pragmatic route:
For high-scale events like IPL matches, we resorted to EC2 instances
Instead of pouring resources into scaling Kubernetes, we invested time into building a switcher — a mechanism that shifted traffic to EC2 instances when we expected spikes.
This simple switcher eventually evolved into a full-fledged scaler solution, giving us the reliability of EC2 when we needed it most, while still allowing us to experiment with Kubernetes in parallel.
The trade-off was clear: predictability now vs flexibility later. And at cricket scale, predictability was what kept us alive.
Scaler — Inhouse Scaling Solution
That switcher eventually evolved into a full-fledged scaler solution.
It started simple: a predictive scaling strategy. The marketing team would share expected traffic numbers before big matches, we looked at DAU, and from there we planned the number of EC2 instances we’d need.
The scaler worked off calendar events, each tagged with a scale profile:
High-scale for IPL and international cricket.
Medium-scale for smaller matches or anticipated spikes.
Low-scale for regular days.
And to optimize cost, we also introduced a night-time-scale, dialing resources down when traffic naturally dropped.
This hybrid model gave us predictability when it mattered most, and cost efficiency when it didn’t — while still leaving room to experiment with Kubernetes in the background.
👉 If you’d like me to go deeper into how this inhouse scaler worked, let me know — I can cover it in a dedicated post.
Closing thoughts
Cricket scale forced us to move faster than we planned. It showed us that scaling infrastructure isn’t about chasing the latest tool — it’s about making trade-offs that match your workload and stage of growth.
Loved the post :)
It shows crucial decision making at the same time knowing technical challenges at the hand. Would love to see dedicated post on in-house scaling solution.
Good one,
Do have a detailed post on scaler solution.